
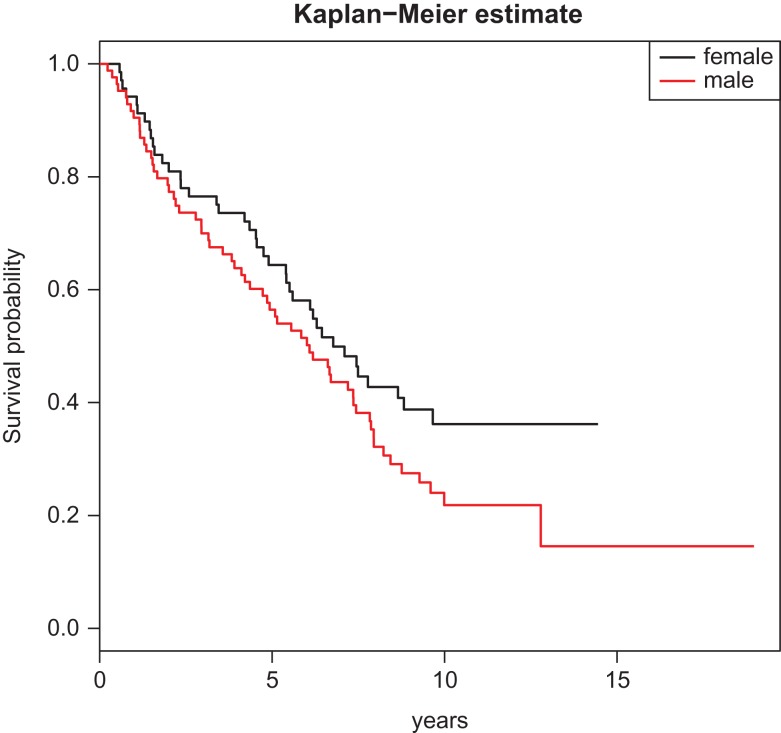
Quantile regression for survival data in modern cancer research: expanding statistical tools for precision medicine.
Quantile regression hyperlinks the entire distribution of an final result to the covariates of curiosity and has grow to be an vital various to generally […]